DEMO³
Multi-Stage Manipulation with Demonstration-Augmented Reward, Policy, and World Model Learning
Adrià López Escoriza1,2, Nicklas Hansen1, Stone Tao1,3, Tongzhou Mu1, Hao Su1,3
UC San Diego, ETH Zürich, Hillbot
ICML 2025
DEMO³
Multi-Stage Manipulation with Demonstration-Augmented Reward, Policy, and World Model Learning
Adrià López Escoriza1,2, Nicklas Hansen1, Stone Tao1,3, Tongzhou Mu1, Hao Su1,3
UC San Diego, ETH Zürich, Hillbot
ICML 2025


Long-horizon tasks in robotic manipulation present significant challenges in reinforcement learning (RL) due to the difficulty of designing dense reward functions and effectively exploring the expansive state-action space. However, despite a lack of dense rewards, these tasks often have a multi-stage structure, which can be leveraged to decompose the overall objective into manageable sub-goals. In this work, we propose DEMO³, a framework that exploits this structure for efficient learning from visual inputs. Specifically, our approach incorporates multi-stage dense reward learning, a bi-phasic training scheme, and world model learning into a carefully designed demonstration-augmented RL framework that strongly mitigates the challenge of exploration in long-horizon tasks. Our evaluations demonstrate that our method improves data-efficiency by an average of 40% and by 70% on particularly difficult tasks compared to state-of-the-art approaches. We validate this across 16 sparse-reward tasks spanning four domains, including challenging humanoid visual control tasks using as few as five demonstrations.
Our method uses small number of demonstrations to (i) pretrain a policy, (ii) train a world model and (iii) learn a multi-stage reward function to guide exploration.
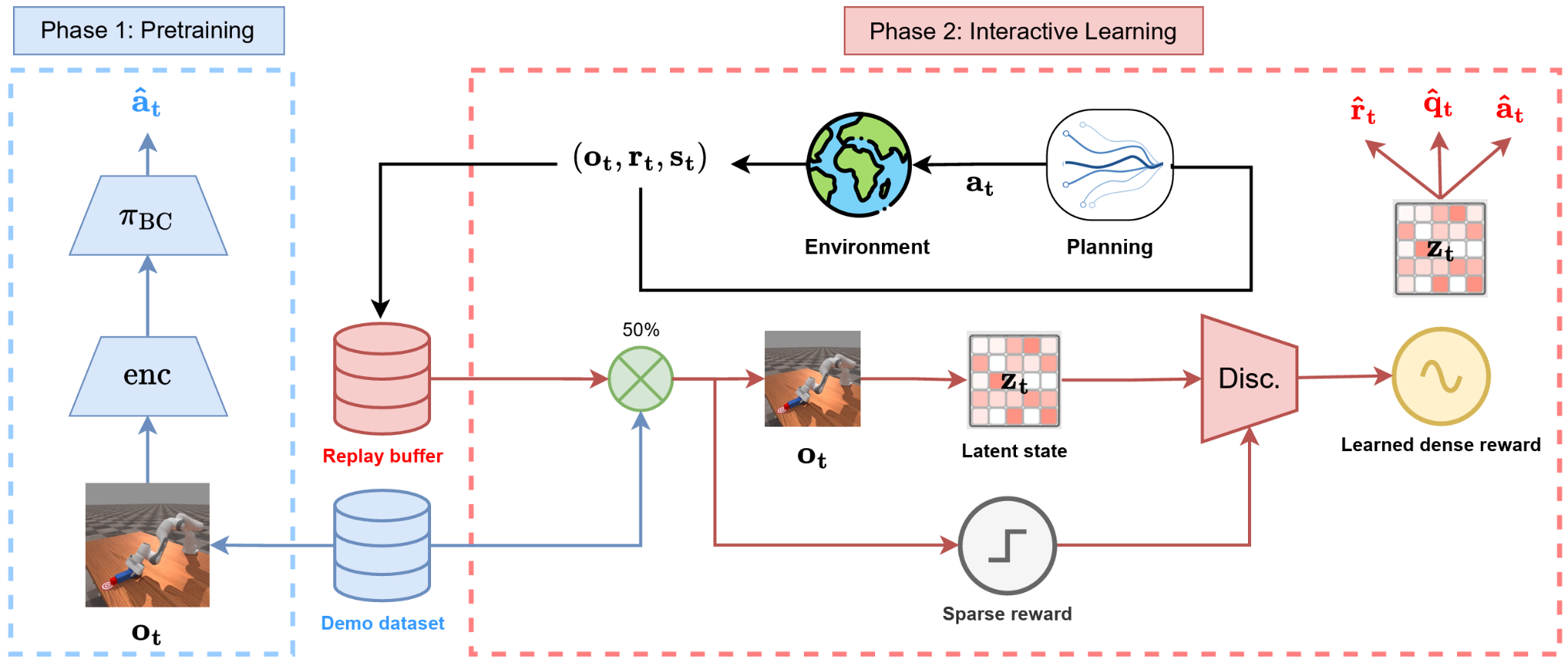
DEMO³ is designed for long-horizon tasks with a multi-stage structure. The agent receives semi-sparse rewards upon completing each stage. For example, in the manipulation tasks below, we break the task into three distinct sub-tasks, each with a clearly identifiable success criterion.












Given a handful of demonstrations, our method achieves high success rates in challenging visual manipulation tasks with sparse rewards, far exceeding previous state-of-the-art methods.
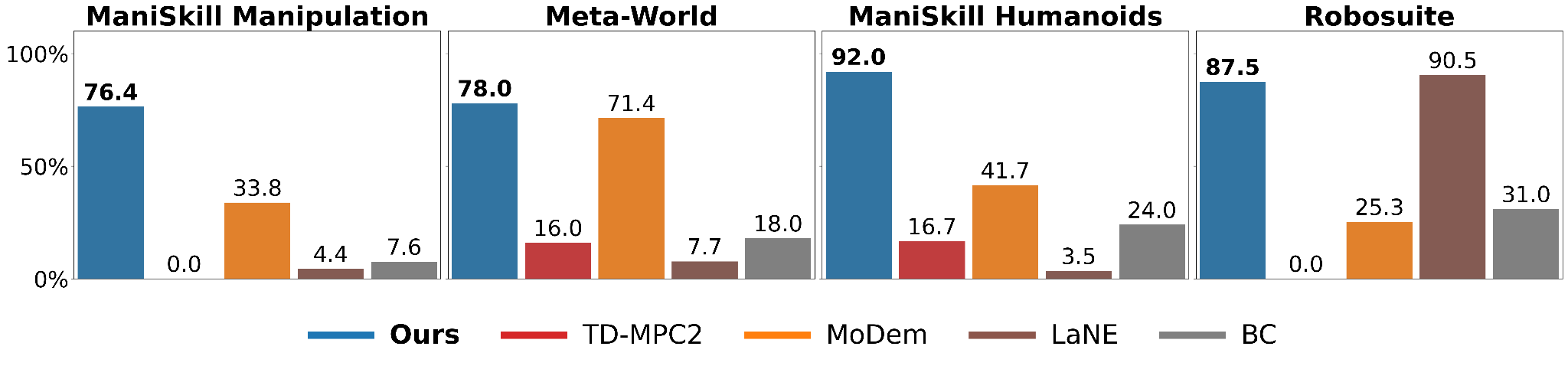
We compare against state-of-the-art methods in three challenging manipulation benchmarks: ManiSkill3, Meta-World, and Robosuite. We additionally test humanoid manipulation tasks in the ManiSkill3 benchmark. Our method is the only one to successfully solve all tasks in the given interaction budget.
DEMO³




MoDem




LaNE




TD-MPC2




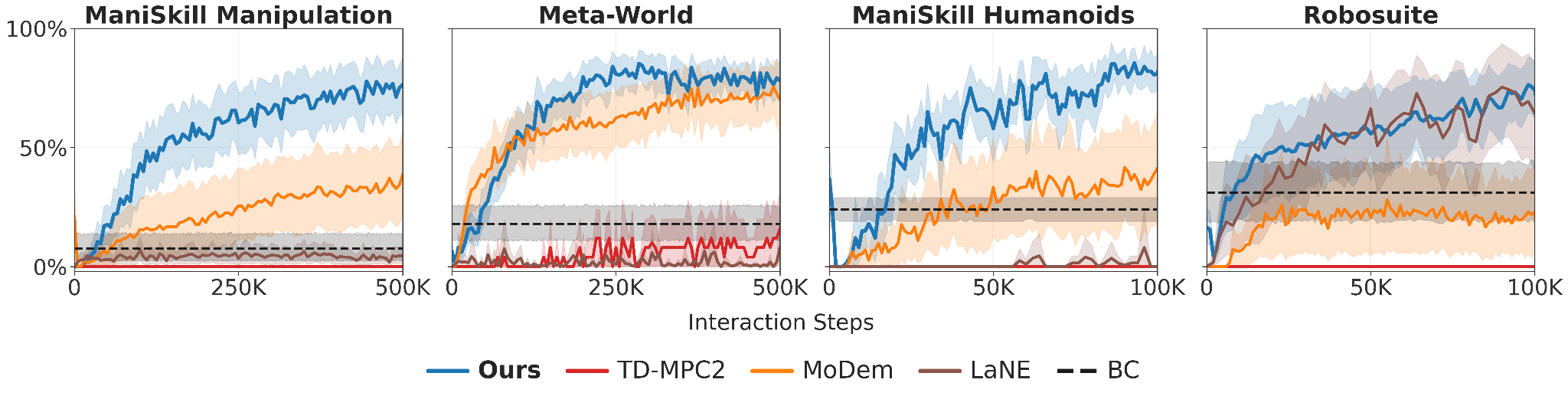
DEMO³ manages to converge to robust solutions in less than 100K steps in difficult manipulation tasks and 0.5M in extremely randomized environments. In some cases, with less than 5 expert demonstrations.
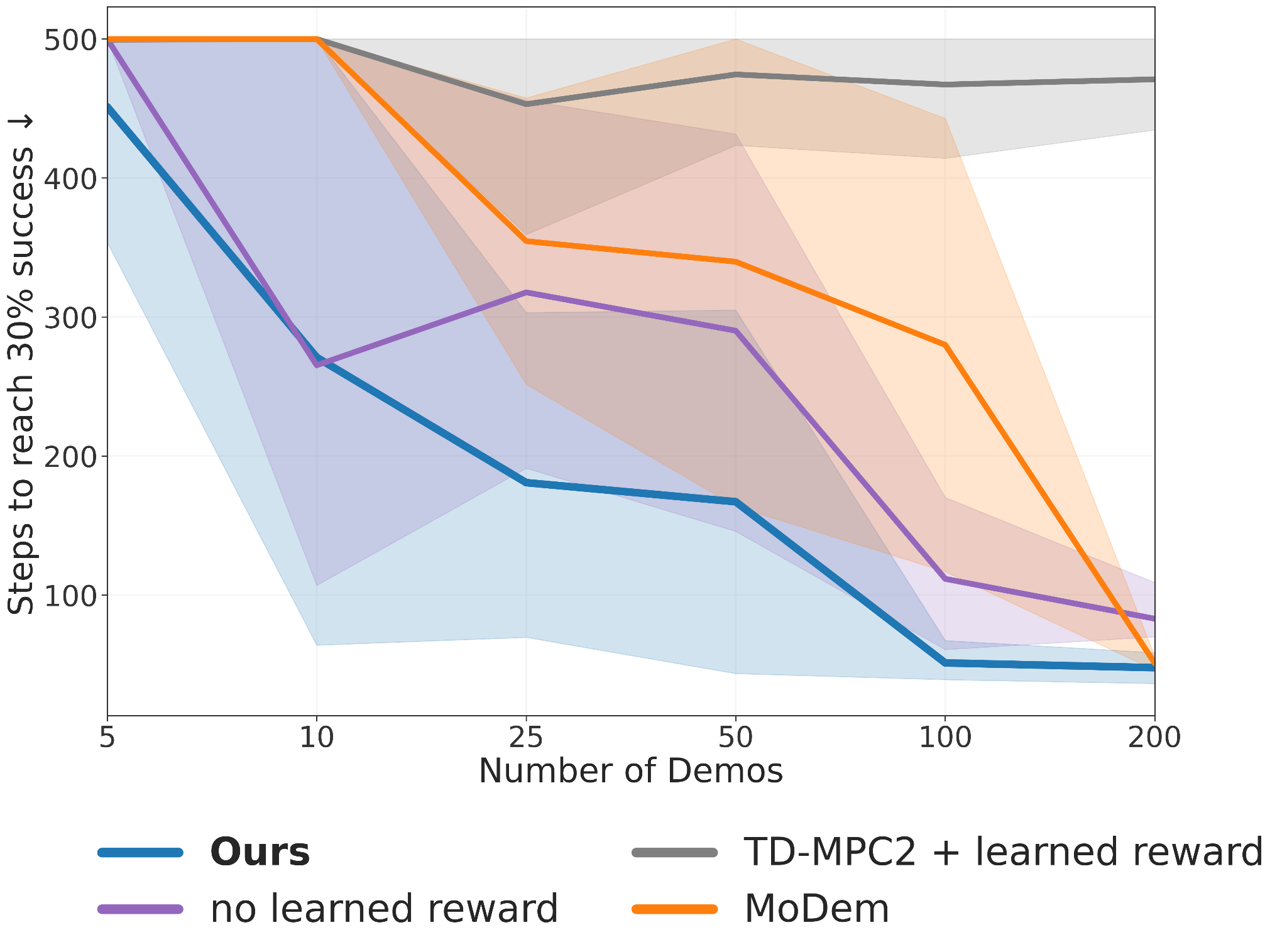
Our approach is significantly more demonstration-efficient than previous methods. We evaluate the convergence of various techniques under a decreasing number of demonstrations in highly challenging tasks. Our results show that DEMO³ is the only method capable of consistently solving tasks with extreme randomization using fewer than 10 demonstrations in under 0.5 million steps. Furthermore, our method scales effectively with the number of demonstrations.
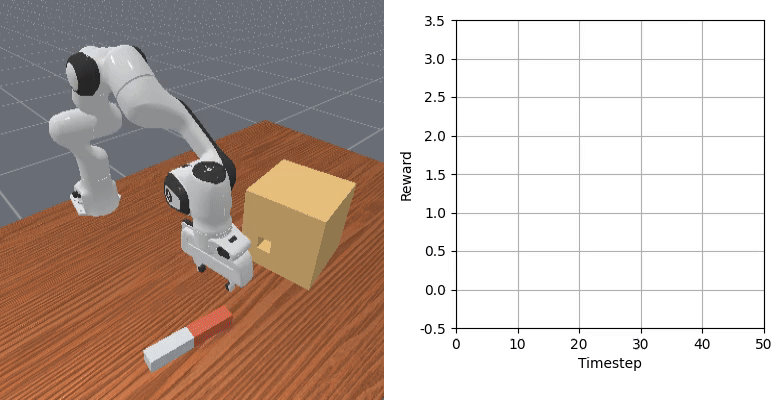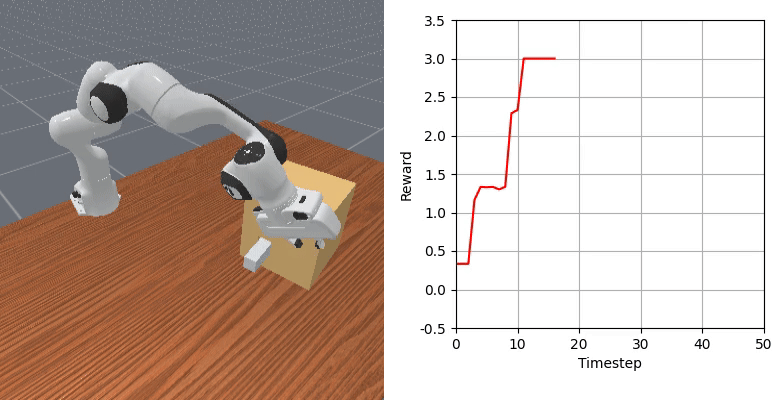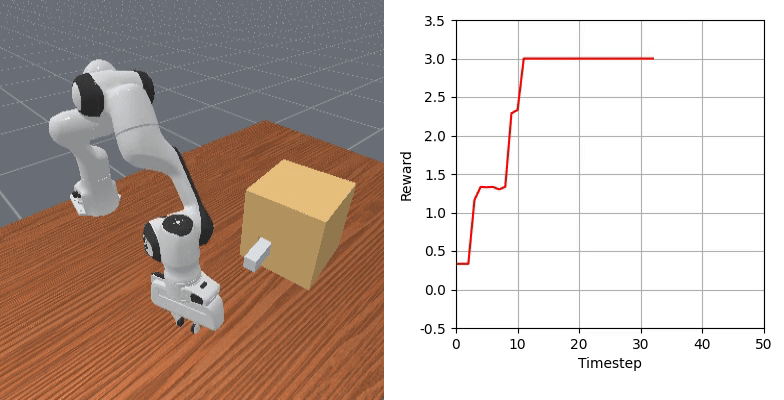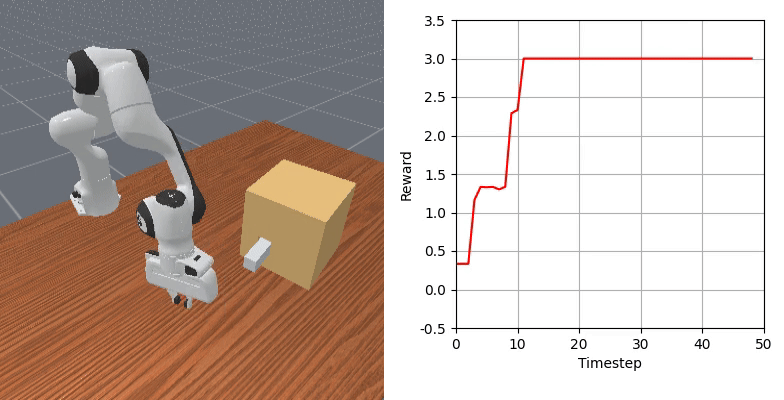
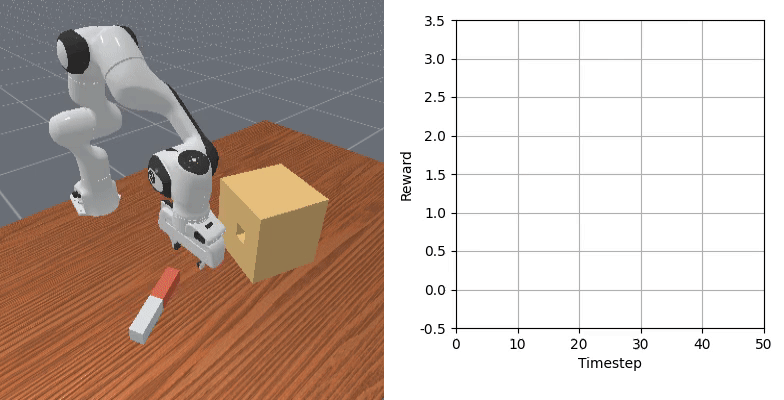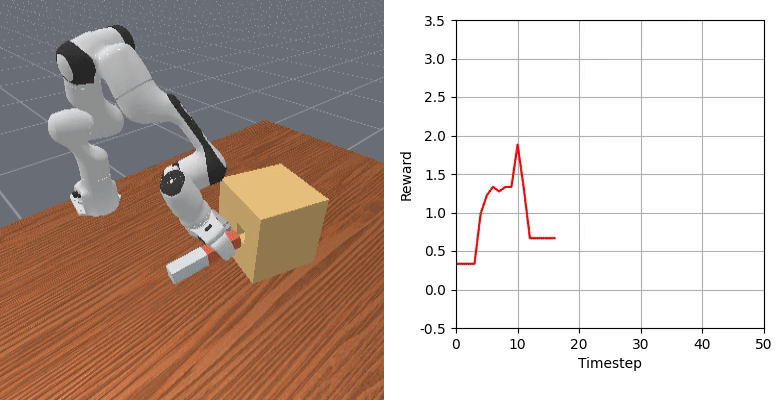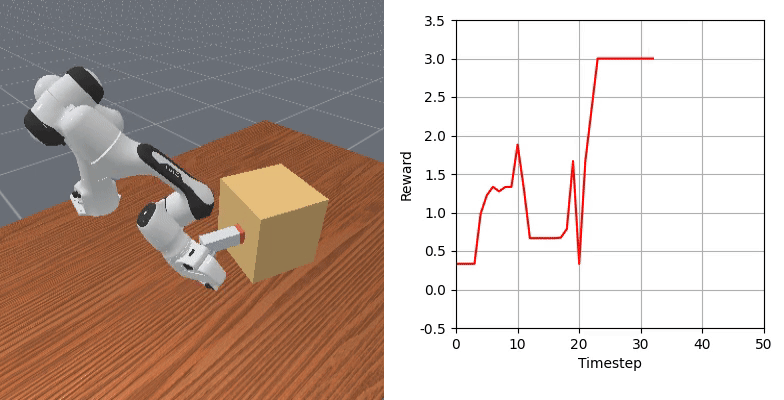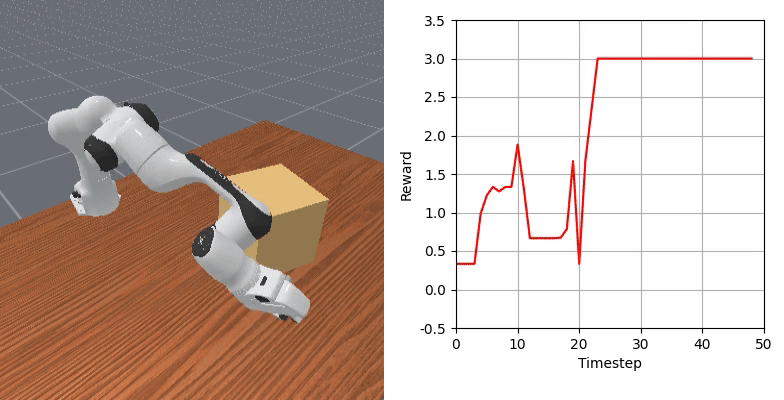
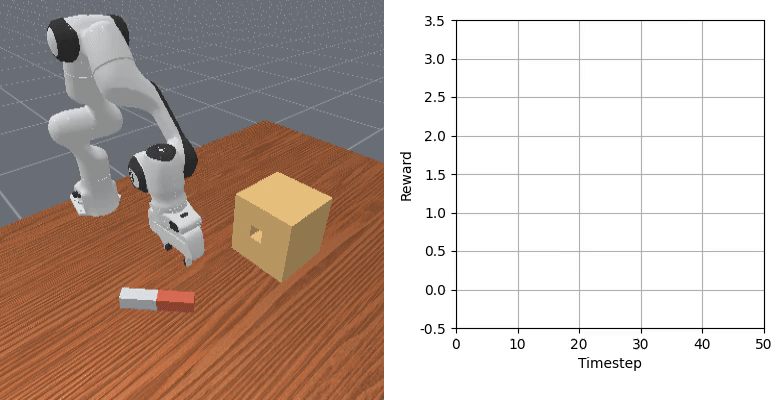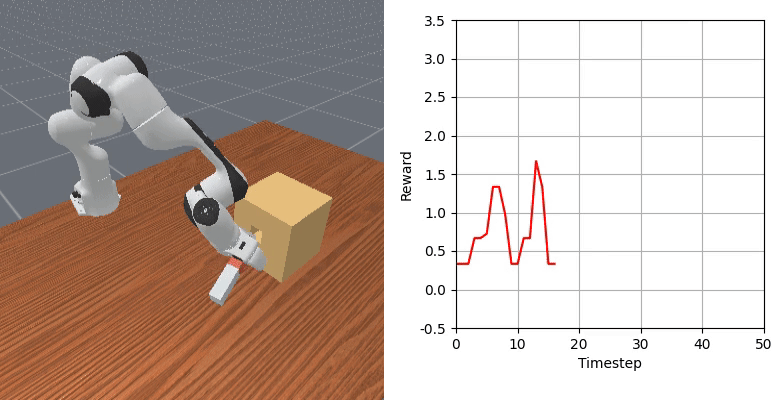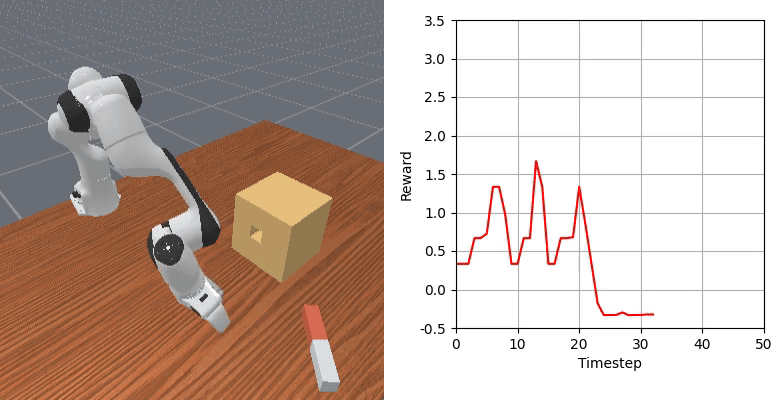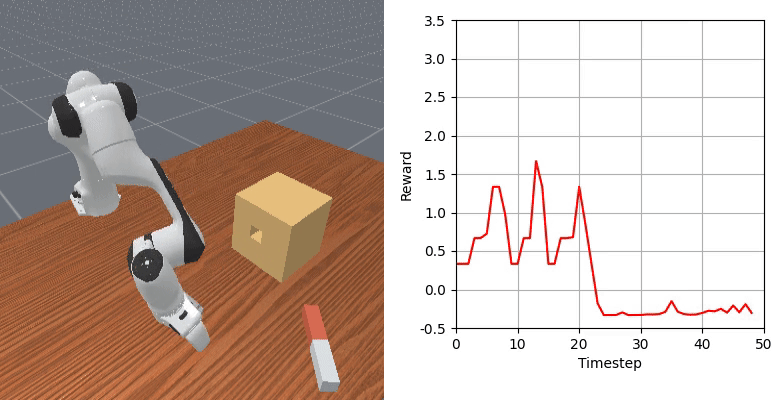
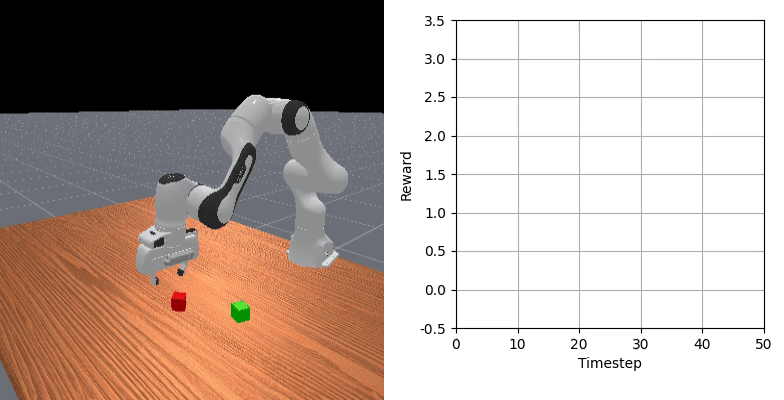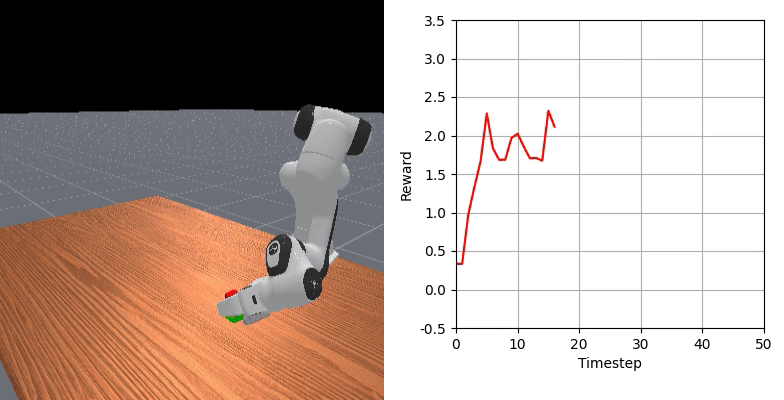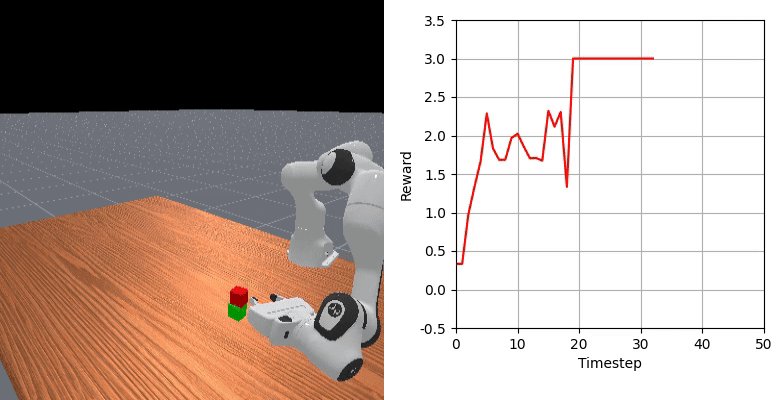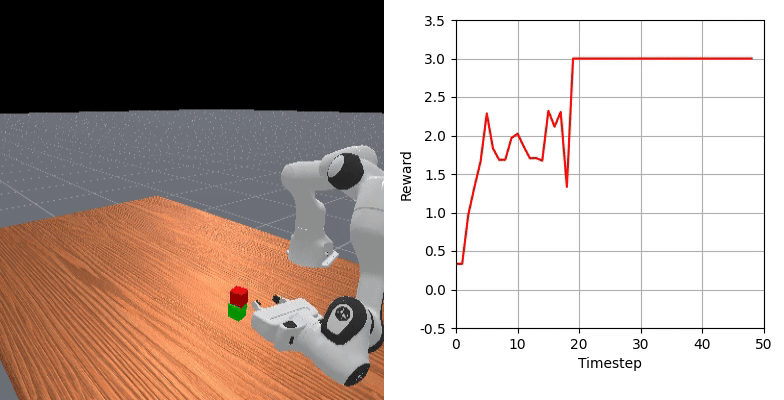
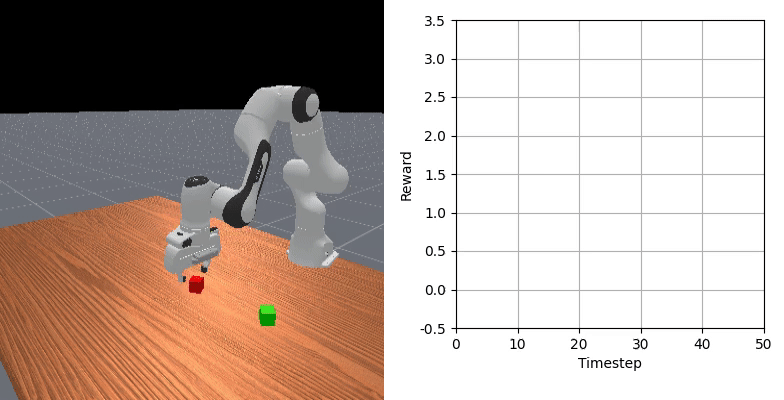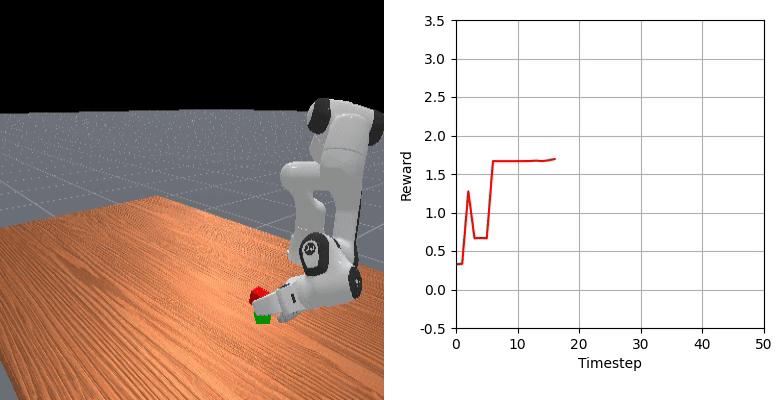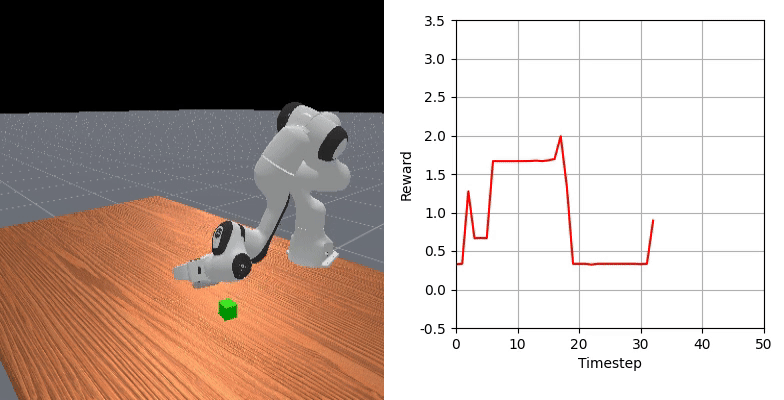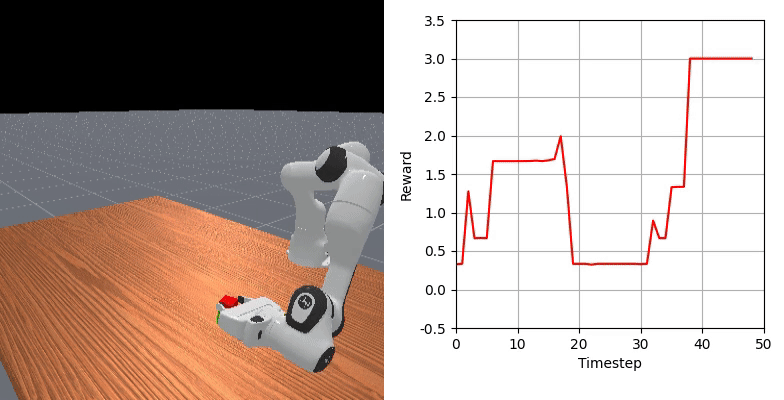
We show that our learned dense reward consistently aligns with task progress.

If you find our work useful, please consider citing the paper as follows:
@misc{escoriza2025multistagemanipulationdemonstrationaugmentedreward,
title={Multi-Stage Manipulation with Demonstration-Augmented Reward, Policy, and World Model Learning},
author={Adrià López Escoriza and Nicklas Hansen and Stone Tao and Tongzhou Mu and Hao Su},
year={2025},
eprint={2503.01837},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2503.01837},
}